


Những lỗi thiết kế cơ sở dữ liệu thường gặp phải của các lập trình viên, lỗi thiết kế Database dẫn đến những rủi ro cho chất lượng dự án.
Rõ ràng, nếu bạn không có kỹ năng kỹ thuật, bạn sẽ không biết làm gì. Không có gì đáng ngạc nhiên khi thấy những lỗi này trong danh sách, non-technical skills (kỹ năng phi kỹ thuật). Mọi người có thể quên chúng, nhưng những kỹ năng này cũng là một phần rất quan trọng của quá trình thiết kế, chúng tạo thêm giá trị cho code của bạn và liên quan đến những vấn đề về công nghệ trong thực tế mà bạn cần giải quyết.

Sau đây LPTech sẽ đưa ra các Lỗi thiết kế CSDL dẫn đến chất lượng dự án kém.
Lỗi thiết kế cơ sở dữ liệu Poor planning
Đây chắc chắn là một vấn đề phi kỹ thuật, nhưng nó là một vấn đề lớn và phổ biến. Tất cả chúng ta đều cảm thấy phấn khích khi một dự án thiết kế website chuyên nghiệp mới bắt đầu và, đi sâu vào nó, mọi thứ đều tuyệt vời. Khi bắt đầu, dự án vẫn là một trang giấy trắng và bạn và khách hàng của bạn rất vui khi bắt đầu làm việc trên một cái gì đó sẽ tạo ra một tương lai tốt hơn cho cả hai.
Tất cả lúc này đều tuyệt vời, và một tương lai tuyệt vời có thể sẽ là kết quả cuối cùng. Nhưng chúng ta cần phải tập trung. Đây là một phần của dự án nơi chúng ta có thể phạm sai lầm nghiêm trọng.
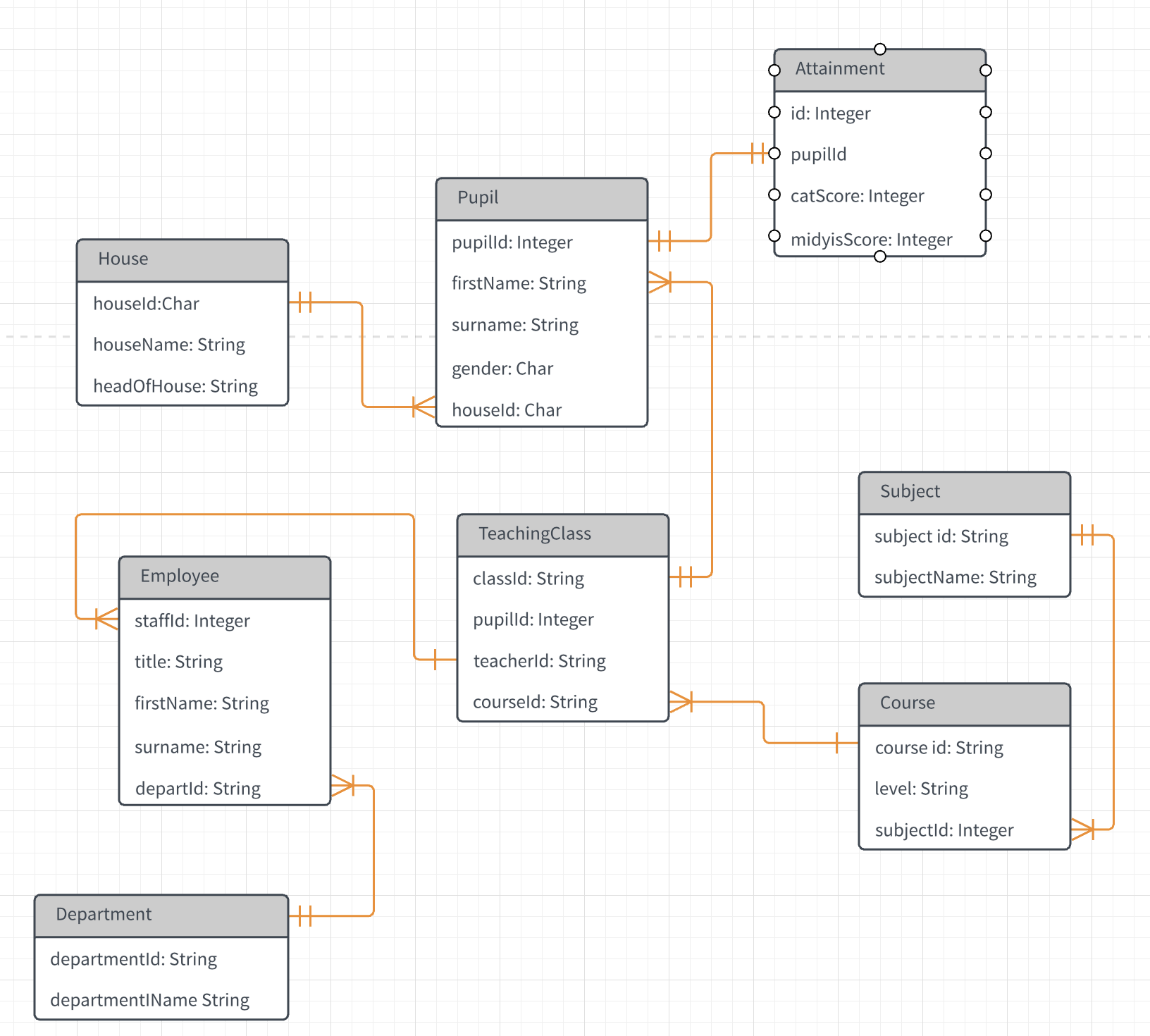
Trước khi bạn ngồi vẽ một mô hình dữ liệu, bạn cần chắc chắn rằng:
- Bạn hoàn toàn nhận thức được những gì khách hàng của bạn làm (tức là các kế hoạch kinh doanh của họ liên quan đến dự án này và cả bức tranh tổng thể của họ) và những gì họ muốn dự án này đạt được ngay bây giờ và trong tương lai.
- Bạn hiểu quy trình kinh doanh và khi cần, bạn đã sẵn sàng đưa ra các đề xuất để đơn giản hóa và cải thiện nó (ví dụ: để tăng hiệu quả và thu nhập, giảm chi phí và giờ làm việc, v.v.).
- Bạn hiểu luồng dữ liệu trong công ty của khách hàng. Lý tưởng nhất là bạn biết mọi chi tiết: ai làm việc với dữ liệu, ai thực hiện thay đổi, báo cáo nào là cần thiết, khi nào và tại sao tất cả những điều này xảy ra.
- Bạn có thể sử dụng ngôn ngữ / thuật ngữ khách hàng của bạn sử dụng. Mặc dù bạn có thể hoặc không thể là một chuyên gia trong lĩnh vực của họ, khách hàng của bạn chắc chắn là như vậy. Yêu cầu họ giải thích những gì bạn không hiểu. Và khi bạn giải thích chi tiết kỹ thuật cho khách hàng, hãy sử dụng ngôn ngữ và thuật ngữ họ hiểu.
- Bạn biết những công nghệ nào bạn sẽ sử dụng, từ công cụ cơ sở dữ liệu và ngôn ngữ lập trình đến các công cụ khác. Những gì bạn quyết định sử dụng có liên quan chặt chẽ đến vấn đề bạn sẽ giải quyết, nhưng điều quan trọng là bao gồm các tùy chọn của khách hàng và cơ sở hạ tầng CNTT hiện tại của họ.
Trong giai đoạn lập kế hoạch, bạn sẽ nhận được câu trả lời cho những câu hỏi sau:
- Những bảng nào sẽ là bảng trung tâm trong mô hình của bạn? Bạn có thể có một vài trong số chúng, trong khi các bảng khác sẽ là một số bảng thông thường (ví dụ: user_account, role). Đừng quên từ điển và quan hệ giữa các bảng.
- Những tên nào sẽ được sử dụng cho các bảng trong mô hình? Hãy nhớ giữ thuật ngữ tương tự như bất cứ điều gì khách hàng hiện đang sử dụng.
- Quy tắc nào sẽ được áp dụng khi đặt tên bảng và các đối tượng khác?
- Toàn bộ dự án sẽ mất bao lâu? Điều này rất quan trọng, cả về lịch trình của bạn và dòng thời gian của khách hàng.
- Chỉ khi bạn có tất cả những câu trả lời này, bạn mới sẵn sàng chia sẻ một giải pháp ban đầu cho vấn đề. Giải pháp đó không cần phải là một ứng dụng hoàn chỉnh - có thể là một tài liệu ngắn hoặc thậm chí một vài câu bằng ngôn ngữ kinh doanh của khách hàng.
Kế hoạch tốt không cụ thể cho mô hình dữ liệu; nó có thể áp dụng cho hầu hết mọi dự án CNTT (và không phải CNTT). Bỏ qua chỉ là một lựa chọn nếu 1) bạn có một dự án thực sự nhỏ; 2) các nhiệm vụ và mục tiêu rõ ràng và 3) bạn đang rất vội.
Một ví dụ lịch sử là các kỹ sư khởi động Sputnik 1 đưa ra các hướng dẫn bằng lời nói cho các kỹ thuật viên đang lắp ráp nó. Dự án đã vội vàng vì tin rằng Hoa Kỳ đang có kế hoạch phóng vệ tinh của riêng họ sớm - nhưng tôi đoán bạn sẽ không vội vàng như vậy.
Communication Developer hàng và Customer chưa tốt
Khi bạn bắt đầu quá trình thiết kế cơ sở dữ liệu, có lẽ bạn sẽ hiểu hầu hết các yêu cầu chính. Một số yêu cầu rất phổ biến bất kể dự án nào, ví dụ như vai trò và trạng thái của người dùng. Mặt khác, một số bảng trong mô hình của bạn sẽ khá cụ thể.
Ví dụ: nếu bạn đang xây dựng mô hình cho một công ty taxi, bạn sẽ có các bảng cho xe cộ, tài xế, khách hàng, v.v.
Tuy nhiên, không phải mọi thứ sẽ rõ ràng khi bắt đầu một dự án. Bạn có thể hiểu sai một số yêu cầu, khách hàng có thể thêm một số chức năng mới, bạn sẽ thấy điều gì đó có thể được thực hiện khác đi, quy trình có thể thay đổi, v.v ... Tất cả những điều này gây ra thay đổi trong mô hình.
Hầu hết các thay đổi đều yêu cầu thêm bảng mới, nhưng đôi khi bạn sẽ xóa hoặc sửa đổi bảng. Nếu bạn đã bắt đầu viết code có sử dụng các bảng này, bạn cũng sẽ cần phải viết lại code đó.
Để giảm thời gian dành cho những thay đổi bất ngờ, bạn nên:
- Nói chuyện với đội phát triển và khách hàng và đừng ngại hỏi những câu hỏi kinh doanh quan trọng. Khi bạn nghĩ rằng bạn đã sẵn sàng để bắt đầu, hãy tự hỏi liệu tình huống X có được bao phủ trong cơ sở dữ liệu của chúng tôi không? Khách hàng hiện đang làm theo cách Y này; chúng ta có mong đợi một sự thay đổi trong tương lai gần không? Khi chúng ta tự tin rằng mô hình của chúng ta có khả năng lưu trữ mọi thứ chúng ta cần theo đúng cách, chúng ta có thể bắt đầu code.
- Nếu bạn phải đối mặt với một sự thay đổi lớn trong thiết kế của bạn và bạn đã có rất nhiều code được viết, bạn không nên thử hot fix. Làm điều đó như nó đã được thực hiện, bất kể tình hình hiện tại. Một hot fix có thể tiết kiệm một số thời gian bây giờ và có thể sẽ hoạt động tốt trong một thời gian, nhưng nó có thể biến thành một cơn ác mộng thực sự sau đó.
- Nếu bạn nghĩ rằng một cái gì đó ổn bây giờ nhưng có thể trở thành một vấn đề sau này, đừng bỏ qua nó. Phân tích khu vực đó và thực hiện các thay đổi nếu chúng sẽ cải thiện chất lượng và hiệu suất của hệ thống. Nó sẽ tốn một thời gian, nhưng bạn sẽ cung cấp một sản phẩm tốt hơn và ngủ ngon hơn nhiều.
- Nếu bạn cố gắng tránh thực hiện thay đổi trong mô hình dữ liệu của mình khi bạn gặp sự cố tiềm ẩn - hoặc nếu bạn chọn cách khắc phục nhanh thay vì thực hiện đúng cách - bạn sẽ trả giá cho điều đó chỉ là sớm hay muộn.
Ngoài ra, hãy giữ liên lạc với khách hàng và đội phát triển trong suốt dự án. Luôn kiểm tra và xem nếu có bất kỳ thay đổi nào được thực hiện kể từ cuộc thảo luận cuối cùng.
Tài liệu nghèo nàn
Đối với hầu hết chúng ta, documentation sẽ hoàn thiện vào cuối dự án. Nếu được tổ chức tốt, có lẽ chúng ta đã ghi lại mọi thứ trong suốt quá trình thực hiện dự án và chúng ta sẽ chỉ cần đóng gói lại mọi thứ. Nhưng thành thật mà nói, đó thường không phải là điều chúng ta thường làm. Viết tài liệu được thực hiện ngay trước khi dự án kết thúc - và ngay sau khi chúng ta hoàn thành công việc với mô hình dữ liệu đó!
Cái giá phải trả cho một dự án có tài liệu kém có thể khá cao, cao hơn một vài lần so với giá chúng ta phải trả để ghi chép đúng mọi thứ. Hãy tưởng tượng bạn tìm thấy một lỗi trong vài tháng sau khi bạn đóng dự án. Bởi vì bạn không có tài liệu đúng, bạn không biết bắt đầu từ đâu.
Khi bạn đang làm việc, đừng quên viết comment. Giải thích mọi thứ cần giải thích thêm, và về cơ bản hãy viết ra mọi thứ bạn nghĩ sẽ có ích vào một ngày nào đó. Bạn không bao giờ biết khi nào bạn sẽ cần thêm thông tin đó.
Không sử dụng quy ước đặt tên
Bạn không bao giờ biết chắc chắn một dự án sẽ kéo dài bao lâu và nếu bạn có nhiều hơn một người làm việc trên mô hình dữ liệu, thì việc đặt tên các đối tượng trong cơ sở dữ liệu theo quy ước chung là một điều thật sự cần thiết nó sẽ giúp những người trong dự án dễ hiểu hơn về nhưng thứ mà bạn và nhưng người khác đã tạo ra khi thiết kế cơ sở dữ liệu.
Bạn có thể thử bắt đầu xây nhưng quy ước chung bằng cách trả lời hưng câu hỏi sau:
- Tên bảng là số ít hay số nhiều?
- Chúng ta sẽ nhóm các bảng bằng cách sử dụng tên? (Ví dụ: tất cả các bảng liên quan đến client có chứa "client_", tất cả các bảng liên quan đến task đều có chứa "task_", v.v.)
- Chúng ta sẽ sử dụng chữ hoa và chữ thường, hay chỉ chữ thường?
- Tên nào chúng ta sẽ sử dụng cho các cột ID? (Nhiều khả năng, nó sẽ là kiểu "id".)
- Chúng ta sẽ đặt tên khóa ngoại như thế nào? (Rất có thể là id "id_" + tên của bảng được tham chiếu.)
Hãy tưởng tượng sự lộn xộn chúng ta sẽ tạo ra nếu mô hình của chúng ta chứa hàng trăm bảng. Có lẽ chúng ta có thể làm việc với một mô hình như vậy (nếu chúng ta tự tạo ra nó) nhưng chúng ta sẽ khiến ai đó cảm thấy mình không may mắn nếu họ phải làm việc với nó sau chúng ta.
Để tránh các vấn đề trong tương lai với tên, đừng sử dụng các từ dành riêng SQL, các ký tự đặc biệt hoặc khoảng trắng trong chúng.
Vì vậy, trước khi bạn bắt đầu tạo bất kỳ tên nào, hãy tạo một tài liệu đơn giản (có thể chỉ dài vài trang) mô tả quy ước đặt tên bạn đã sử dụng. Điều này sẽ tăng khả năng đọc hiểu của toàn bộ mô hình và đơn giản hóa công việc trong tương lai
Vấn đề về chuẩn hóa
Chuẩn hóa là một phần thiết yếu của thiết kế cơ sở dữ liệu. Mỗi cơ sở dữ liệu phải được chuẩn hóa thành ít nhất 3NF (các khóa chính được xác định, các cột là nguyên tử và không có các nhóm lặp lại, phụ thuộc một phần hoặc phụ thuộc bắc cầu). Điều này làm giảm sự trùng lặp dữ liệu và đảm bảo tính toàn vẹn tham chiếu.
Sử dụng Mô hình Entity-Attribute-Value (EAV)
EAV là viết tắt của Thực thể - Thuộc tính - Giá trị (Entity-Attribute-Value). Cấu trúc này có thể được sử dụng để lưu trữ dữ liệu bổ sung về bất cứ điều gì trong mô hình của chúng ta.
Hãy cùng xem một ví dụ. Giả sử rằng chúng ta muốn lưu trữ một số thuộc tính khách hàng bổ sung. Bảng "customer" là thực thể của chúng ta, bảng "attribute" rõ ràng là chứa các thuộc tính của chúng ta, và bảng "attribute_value" có chứa giá trị của thuộc tính cho khách hàng nào đó.
Đầu tiên, chúng ta sẽ thêm một dictionary với một danh sách tất cả các thuộc tính có thể chúng ta có thể gán cho một khách hàng. Đây là bảng "attribute". Nó có thể chứa các thuộc tính như “customer value”, “contact details”, “additional info” v.v. Bảng "customer_attribute" bào gồm một danh sách tất cả các thuộc tính với giá trị cho mỗi customer.
Đối với mỗi customer, chúng ta sẽ chỉ có các bản ghi cho các thuộc tính mà họ có và chúng ta sẽ lưu trữ "attribute_value" cho thuộc tính đó. Điều này có vẻ thực sự tuyệt vời. Nó sẽ cho phép chúng ta thêm các thuộc tính mới một cách dễ dàng (bởi vì chúng ta thêm chúng dưới dạng các giá trị trong bảng "customer_attribute".
Vì vậy, chúng ta sẽ tránh thực hiện thay đổi trong cơ sở dữ liệu, nó là quá tốt. Trong khi mô hình sẽ lưu trữ dữ liệu chúng ta cần, làm việc với dữ liệu đó phức tạp hơn nhiều. Và bao gồm hầu hết mọi thứ, từ viết các truy vấn SELECT đơn giản đến nhận tất cả các giá trị liên quan đến khách hàng đến chèn, cập nhật hoặc xóa các giá trị. Nói tóm lại, chúng ta nên tránh cấu trúc EAV.
Nếu bạn phải sử dụng nó, chỉ sử dụng nó khi bạn chắc chắn 100% rằng nó thực sự cần thiết.
Sử dụng GUID / UUID làm Khóa chính
GUID Globally Unique Identifier) là số 128 bit được tạo theo quy tắc được xác định trong RFC 4122. Đôi khi chúng còn được gọi là UUID (Universally Unique Identifiers). Ưu điểm chính của GUID là nó là duy nhất; cơ hội bạn đạt được GUID hai lần là rất khó xảy ra. Do đó, GUID dường như là một ứng cử viên tuyệt vời cho cột khóa chính.
Nhưng không hoàn toàn như vậy.
Một quy tắc chung cho các khóa chính là chúng ta sử dụng một cột số nguyên với thuộc tính autoincrement được đặt thành có. Điều này sẽ thêm dữ liệu theo thứ tự tuần tự vào khóa chính và cung cấp hiệu suất tối ưu. Nếu không có khóa tuần tự hoặc dấu thời gian, thì không có cách nào để biết dữ liệu nào được chèn trước. Vấn đề này cũng phát sinh khi chúng ta sử dụng các giá trị UNIQUE real-world (ví dụ: ID VAT).
Đánh index không đầy đủ
Các index là một phần rất quan trọng khi làm việc với cơ sở dữ liệu, nhưng để thảo luận kỹ lưỡng về chúng nằm ngoài phạm vi của bài viết này.
Dư thừa dữ liệu
Dữ liệu dư thừa thường nên tránh trong bất kỳ mô hình nào. Nó không chỉ chiếm thêm dung lượng đĩa mà còn làm tăng đáng kể khả năng xảy ra sự cố toàn vẹn dữ liệu. Nếu có thứ gì đó là dư thừa, chúng ta nên lưu ý rằng dữ liệu gốc và bản sao luôn luôn ở trạng thái nhất quán. Trong thực tế, có một số tình huống mà dữ liệu dư thừa là mong muốn:
Trong một số trường hợp, chúng ta phải gán mức độ ưu tiên cho một hành động nhất định - và để thực hiện điều này, chúng ta phải thực hiện các phép tính phức tạp. Các tính toán này có thể sử dụng nhiều bảng và tiêu tốn nhiều tài nguyên. Trong những trường hợp như vậy, sẽ là khôn ngoan hơn khi thực hiện các tính toán này trong giờ nghỉ (do đó tránh được các vấn đề về hiệu suất trong giờ làm việc). Nếu chúng ta làm theo cách này, chúng ta có thể lưu trữ giá trị được tính toán đó và sử dụng nó sau mà không phải tính toán lại. Tất nhiên, giá trị là dư thừa; tuy nhiên, những gì chúng ta đạt được trong hiệu suất cao hơn đáng kể so với những gì chúng ta mất (một số dung lượng ổ cứng).
Chúng ta cũng có thể lưu trữ một tập hợp nhỏ dữ liệu báo cáo bên trong cơ sở dữ liệu. Ví dụ: vào cuối ngày, chúng ta sẽ lưu trữ số lượng cuộc gọi chúng ta thực hiện vào ngày hôm đó, số lần bán hàng thành công, v.v. Dữ liệu báo cáo chỉ nên được lưu trữ theo cách này nếu chúng ta cần sử dụng thường xuyên. Một lần nữa, chúng ta sẽ mất một ít dung lượng ổ cứng, nhưng chúng ta sẽ tránh tính toán lại dữ liệu hoặc kết nối với cơ sở dữ liệu báo cáo (nếu chúng ta có).
Trong hầu hết các trường hợp, chúng ta không nên sử dụng dữ liệu dư thừa vì:
Lưu trữ cùng một dữ liệu nhiều lần trong cơ sở dữ liệu có thể ảnh hưởng đến tính toàn vẹn dữ liệu. Nếu bạn lưu trữ tên khách hàng ở hai nơi khác nhau, bạn phải thực hiện bất kỳ thay đổi nào (chèn / cập nhật / xóa) cho cả hai địa điểm cùng một lúc. Điều này cũng làm phức tạp code bạn cần, ngay cả đối với các hoạt động đơn giản nhất.
Mặc dù chúng ta có thể lưu trữ một số số tổng hợp trong cơ sở dữ liệu hoạt động của mình, chúng ta chỉ nên làm điều này khi chúng ta thực sự cần. Một cơ sở dữ liệu hoạt động không có nghĩa là để lưu trữ dữ liệu báo cáo và trộn lẫn hai dữ liệu này nói chung là một việc k nên. Bất cứ ai tạo báo cáo sẽ phải sử dụng các tài nguyên giống như người dùng làm việc trong các tác vụ vận hành; truy vấn báo cáo thường phức tạp hơn và có thể ảnh hưởng đến hiệu suất. Do đó, bạn nên tách cơ sở dữ liệu hoạt động và cơ sở dữ liệu báo cáo của bạn.
