


Thu thập dữ liệu (Crawling) là bước quan trọng không thể thiếu để một bài viết được lập chỉ mục và hiển thị trong kết quả tìm kiếm của Google. Việc thu thập dữ liệu cho Google Search được thực hiện bởi Googlebot, một chương trình chạy trên các máy chủ của Google, truy xuất một URL và xử lý các lỗi mạng, chuyển hướng, và các phức tạp nhỏ khác mà nó có thể gặp phải khi làm việc qua web. Trong bài viết mới nhất của Google tháng 12 đã giải thích chi tiết hơn về quá trình Googlebot thu thập dữ liệu trên web, đặc biệt là cách Googlebot xử lý các tài nguyên như JavaScript, CSS, và hình ảnh.
Thu thập dữ liệu (Crawling) là gì?
Thu thập dữ liệu là quá trình khám phá các bài viết mới và thu thập lại các bài viết cũ được cập nhật nội dung và tải chúng về. Googlebot thực hiện việc này bằng cách gửi yêu cầu HTTP đến máy chủ và xử lý các phản hồi, bao gồm theo dõi các chuyển hướng, xử lý lỗi và chuyển nội dung trang đến hệ thống lập chỉ mục của Google.
Tuy nhiên, ngoài HTML, các trang web hiện đại còn sử dụng JavaScript, CSS, hình ảnh và video. Googlebot không chỉ tải HTML mà còn các tài nguyên này để xây dựng trang hoàn chỉnh. Vậy các dữ liệu này ảnh hưởng nào đến ngân sách thu thập dữ liệu?
Cách Googlebot thu thập dữ liệu các tài nguyên trang
Như đã nói ở trên goài HTML, các trang web hiện đại còn sử dụng JavaScript, CSS, hình ảnh và video. Googlebot không chỉ tải HTML mà còn các tài nguyên này để xây dựng trang hoàn chỉnh.
Qúa trình thu thập dữ liệu:
- Bắt đầu bằng việc Googlebot tải dữ liệu HTML từ URL chính của trang.
- Sau khi tải dữ liệu, Googlebot chuyển nó đến WRS (Web Rendering Service)
- WRS sử dụng Googlebot, tải các tài nguyên được tham chiếu trong HTML như JavaScript và CSS.
- WRS sử dụng tất cả các tài nguyên đã tải xuống để xây dựng trang hoàn chỉnh như trình duyệt của người dùng.
Việc thu thập dữ liệu các tài nguyên này tiêu tốn "ngân sách thu thập dữ liệu (crawl budget)" của tên miền lưu trữ tài nguyên. Để tiết kiệm ngân sách, WRS cố gắng lưu trữ tạm thời mọi tài nguyên (JavaScript và CSS) trong tối đa 30 ngày và không bị ảnh hưởng bởi các chỉ thị bộ nhớ cache HTTP. Điều này giúp bảo tồn ngân sách thu thập dữ liệu của trang web cho các nhiệm vụ thu thập khác.
Quản lý tài nguyên để tối ưu hóa ngân sách thu thập dữ liệu
Để tối ưu hóa việc quản lý tài nguyên và ngân sách thu thập dữ liệu (crawl budget) của Googlebot, Google khuyến cáo:
Sử dụng ít tài nguyên
Người dùng nên cố gắng giảm số lượng tài nguyên như JavaScript, CSS, hình ảnh cần thiết để xây dựng trang web. Bằng cách này, khi Googlebot thu thập dữ liệu, nó sẽ tốn ít ngân sách hơn, và các trang sẽ được thu thập và lập chỉ mục nhanh hơn.
Cẩn thận với các tham số phá bộ nhớ cache
Tham số phá bộ nhớ cache thay đổi URL của các tài nguyên (như hình ảnh hoặc CSS) để đảm bảo người dùng luôn nhận được phiên bản mới nhất. Tuy nhiên, nếu thay đổi thường xuyên, Googlebot phải thu thập lại các tài nguyên này, tiêu hao ngân sách thu thập dữ liệu. Do đó, nên sử dụng các tham số này một cách thận trọng để tránh việc không cần thiết phải thu thập lại các tài nguyên không thay đổi.
Lưu trữ tài nguyên trên tên miền phụ hoặc CDN
Bằng cách lưu trữ các tài nguyên như JavaScript, CSS hoặc hình ảnh trên một tên miền phụ hoặc qua các mạng phân phối nội dung (CDN), người dùng có thể chuyển tải ngân sách thu thập dữ liệu sang các tên miền khác. Điều này giúp tiết kiệm ngân sách thu thập dữ liệu của tên miền chính.
Tuy nhiên trong cập nhật ngày 6 tháng 12, 2024, có nhắc đến việc lưu trữ các tài nguyên quan trọng như JavaScript hoặc CSS trên các tên miền phụ có thể làm chậm hiệu suất của trang do chi phí kết nối cao. Vì vậy, không nên sử dụng chiến lược này cho các tài nguyên quan trọng nhưng có thể xem xét cho các tài nguyên lớn không quan trọng như video hoặc tệp tải xuống.
Khi Googlebot tải các tài nguyên như hình ảnh và video, nó tiêu hao một phần ngân sách thu thập dữ liệu của trang web, tương tự như cách nó tải HTML và CSS. Và nếu bạn nghỉ đến việc ngăn chặn Googlebot truy cập các tài nguyên quan trọng thông qua robots.txt thường không được khuyến khích vì sẽ gây ra lỗi trong quá trình kết xuất trang. Điều này có thể dẫn đến việc Google không thể trích xuất nội dung và xếp hạng trang hiệu quả trên kết quả tìm kiếm.
Làm thế nào để biết Googlebot thu thập dữ liệu gì?
Làm cách nào để biết được Googlebot đang thu thập dữ liệu gì trên website của bạn?
Nhật ký thô (raw access log)
Cách tốt nhất là xem ở nhật ký truy cập thô (raw access log) của trang web. Đây là tài liệu ghi lại mọi URL được yêu cầu bởi trình duyệt và trình thu thập dữ liệu (crawler). Nó là nguồn tốt nhất để phân tích chính xác những tài nguyên nào đang được Googlebot thu thập. Google cũng công bố các dải IP của mình trong tài liệu dành cho nhà phát triển. Điều này giúp chủ sở hữu trang web xác định chính xác các yêu cầu đến từ trình thu thập dữ liệu của Google, so sánh với các trình thu thập dữ liệu khác.
Báo cáo thu thập dữ liệu trên Google Search Console
Báo cáo thống kê thu thập dữ liệu trên Google Search Console (Crawl stats) là công cụ tốt thứ hai có thể theo dõi các loại tài nguyên mà Googlebot thu thập trên trang web. Báo cáo này cung cấp một cách chi tiết về các tài nguyên đã được thu thập, giúp chủ sở hữu trang web hiểu rõ hơn về hoạt động của Googlebot.
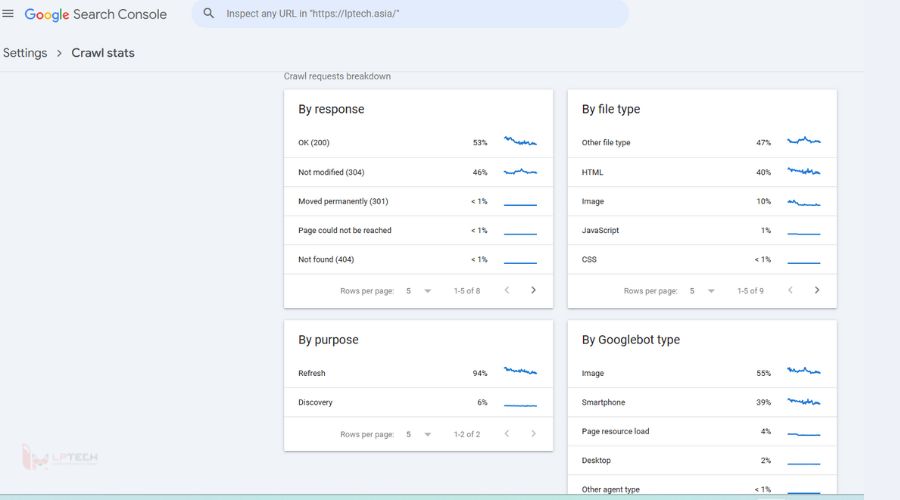
Cộng đồng Search Central
Cuối cùng là Cộng đồng Search Central (Search Central community) là nơi dành cho những người quan tâm sâu sắc đến việc thu thập và kết xuất dữ liệu. Tại đây, mọi người có thể thảo luận và chia sẻ kinh nghiệm về các chủ đề liên quan.
Hiểu được quá trình thu thập dữ liệu của Googlebot, bao gồm việc truy cập và tải xuống các tài nguyên như HTML, JavaScript, CSS, hình ảnh và video để xây dựng trang web và các ảnh hưởng của chúng đến "ngân sách thu thập dữ liệu". Điều này không chỉ giúp tiết kiệm ngân sách thu thập dữ liệu mà còn cải thiện thứ hạng trên công cụ tìm kiếm.
